 源码剖析-组消费模式
源码剖析-组消费模式
# 4.17 Kafka源码剖析之组消费模式
组消费模式指的是在消费者消费消息的时候,使用组协调器的再平衡机制自动分配要消费的分区(们)。
此时需要在消费者的配置中指定消费组ID,同时如果需要,设置偏移量重置的策略。
然后消费者订阅主题,就可以消费消息了。
Map<String, Object> configs = new HashMap<>();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092");
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
configs.put(ConsumerConfig.CLIENT_ID_CONFIG, "mycsmr" +System.currentTimeMillis());
configs.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 设置消费组id
configs.put(ConsumerConfig.GROUP_ID_CONFIG, "csmr_grp_01");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(configs);
consumer.subscribe(Collections.singleton("tp_demo_01"));
ConsumerRecords<String, String> records = consumer.poll(1000);
records.forEach(record -> {
System.out.println(record.topic() + "\t"
+ record.partition() + "\t"
+ record.offset() + "\t"
+ record.key() + "\t"
+ record.value());
}
);
// 最后关闭消费者
consumer.close();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
consumer.subscribe 方法的实现:

上面方法中第一个参数是订阅的主题集合,第二个参数是一个监听器,当发送再平衡的时候消费者想要执行的操作。
默认是NoOpConsumerRebalanceListener,即什么都不做:
NoOpConsumerRebalanceListener的实现:

订阅方法的实现:
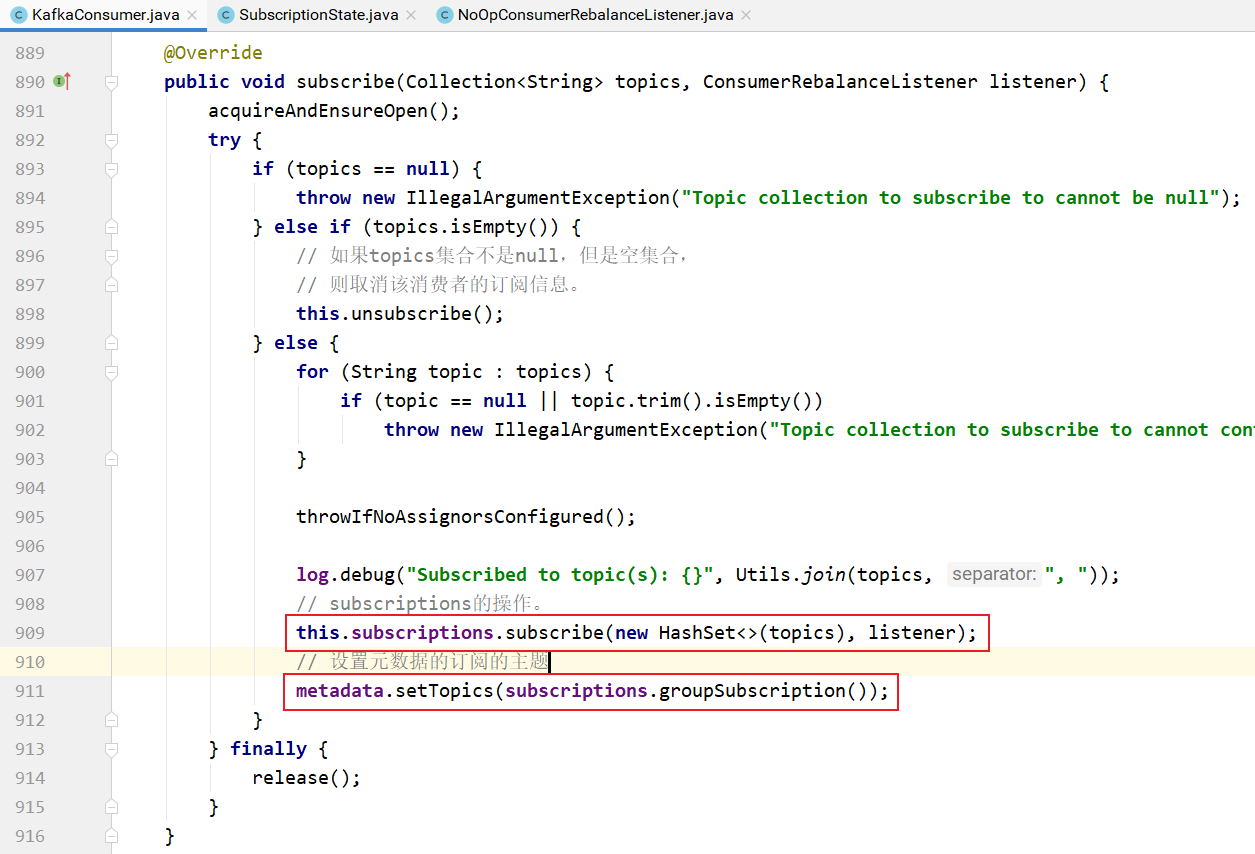
subscriptions的订阅操作实现:
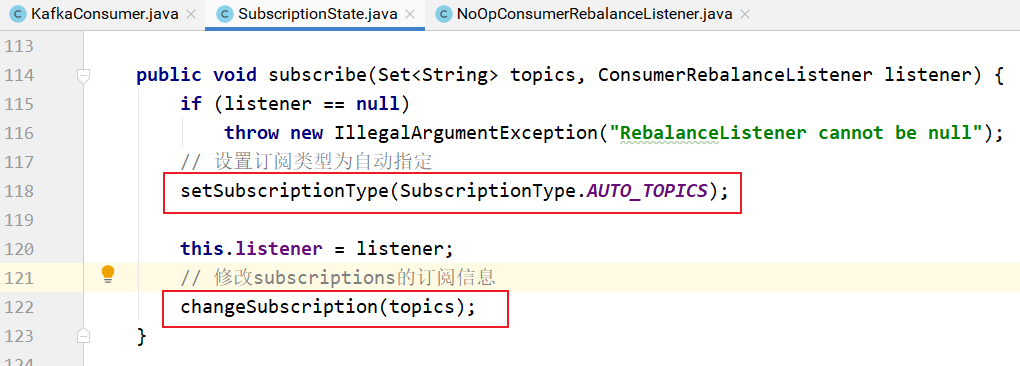
就是对SubscriptionState的操作:

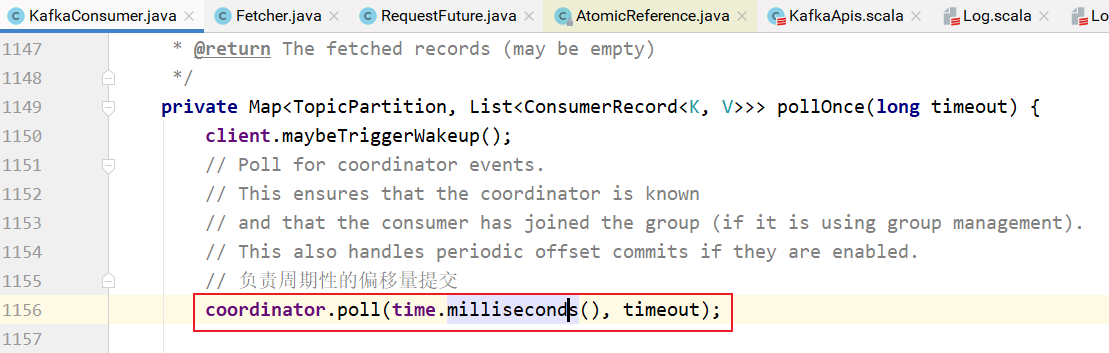
用户的poll的操作调用pollOnce方法:
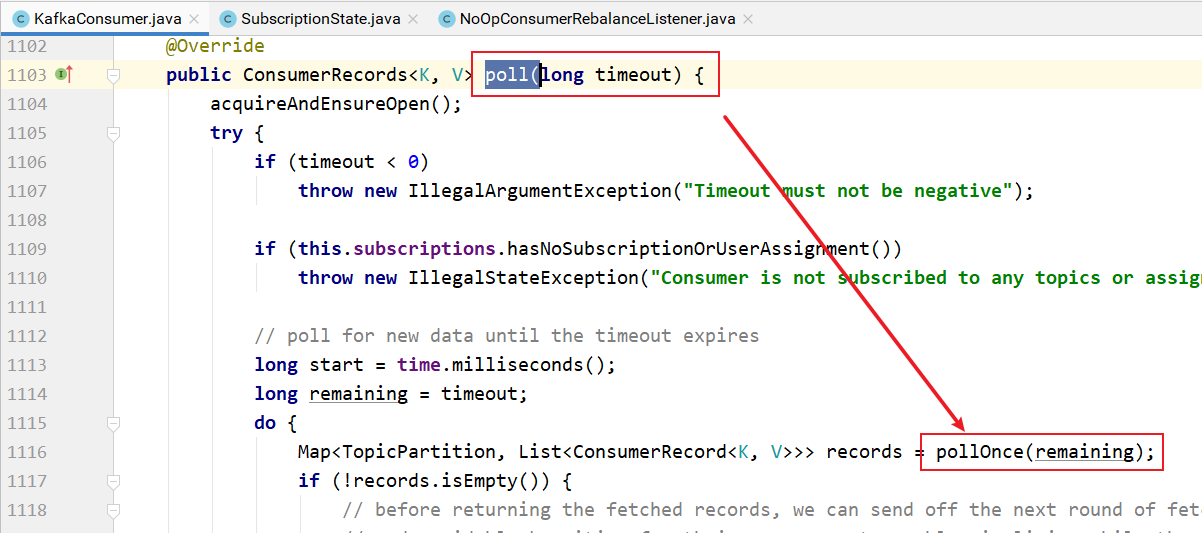
pollOnce的实现:

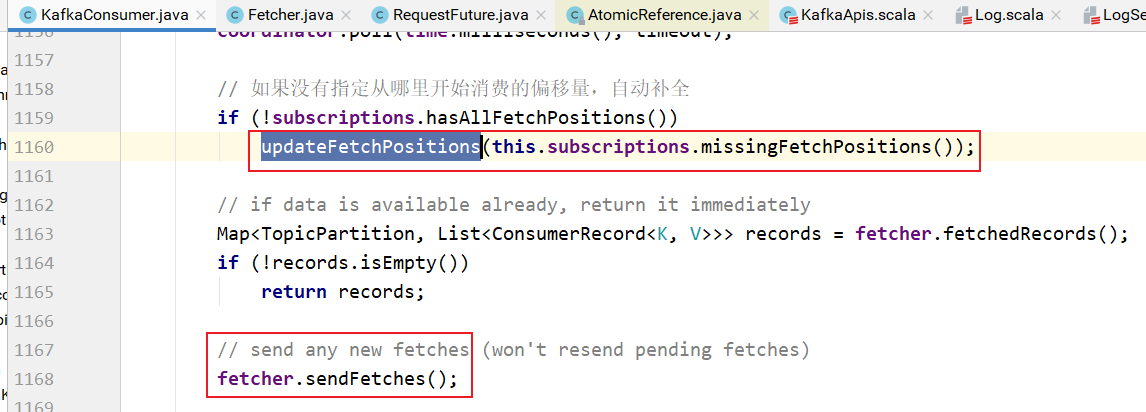
coordinator.poll负责周期性地向broker提交偏移量信息。
上面方法中updateFetchPositions方法表示:如果订阅的主题分区没有偏移量信息,则更新主题分区的偏移量信息,这样就知道消费的时候从哪里开始消费了:
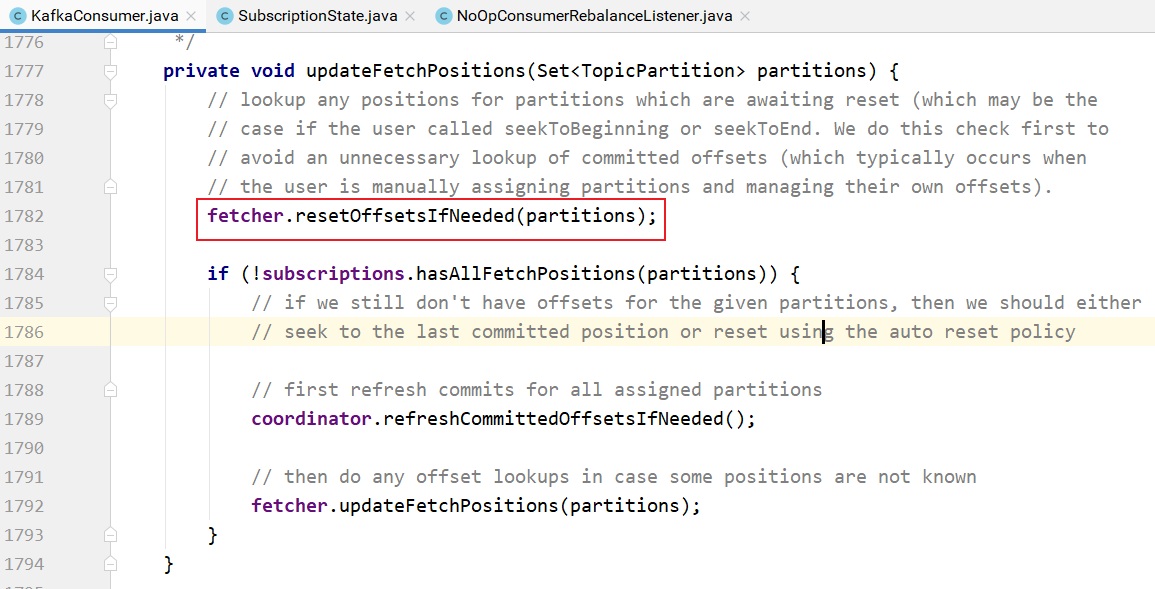
上图中的fetcher.resetOffsetsIfNeeded方法的实现:

resetOffsets的具体实现:


上述的实现表示:首先根据重置策略重置主题分区的偏移量请求类型,然后发送请求,真正从主题的分区中获取偏移量。
其中上图中的

需要向broker发请求,获取主题分区的偏移量,更新偏移量的值:
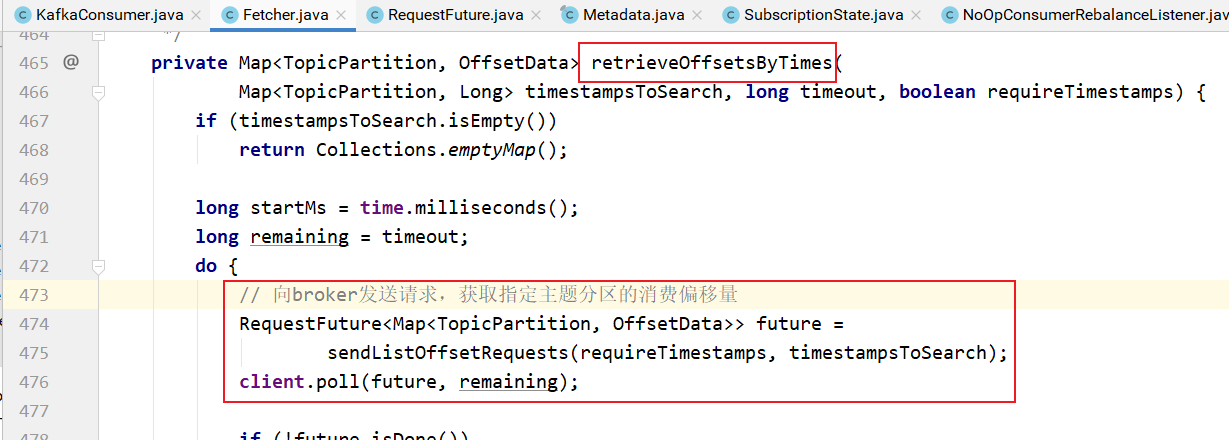
发送请求的实现:


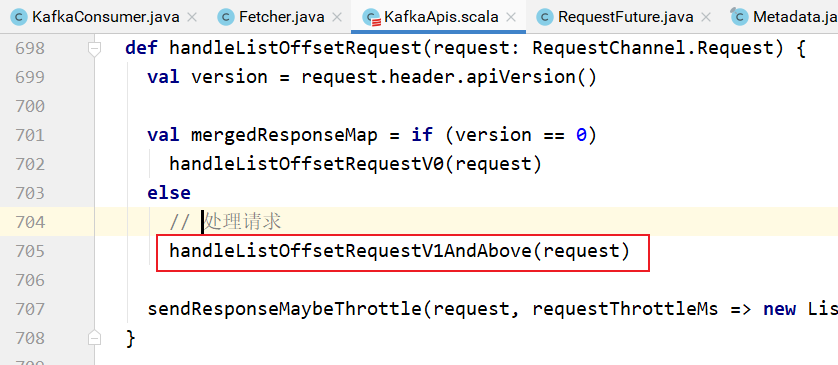
发送的请求是ListOffsetRequest请求:

该请求在Broker中的处理:

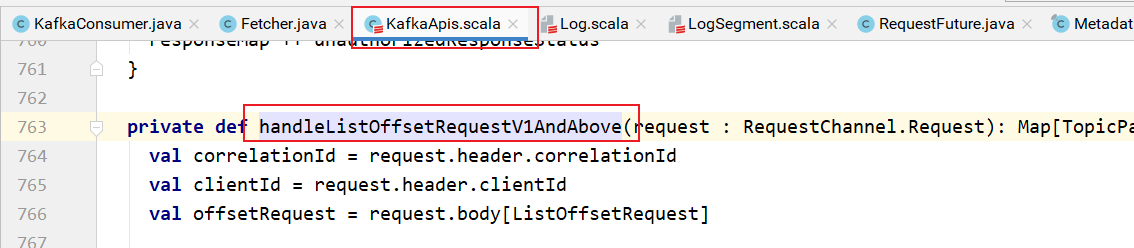
具体处理:
该方法的实现:
如果是最晚的,直接设置最晚的偏移量,如果不是最晚的,则需要根据主题分区以及时间戳查找:
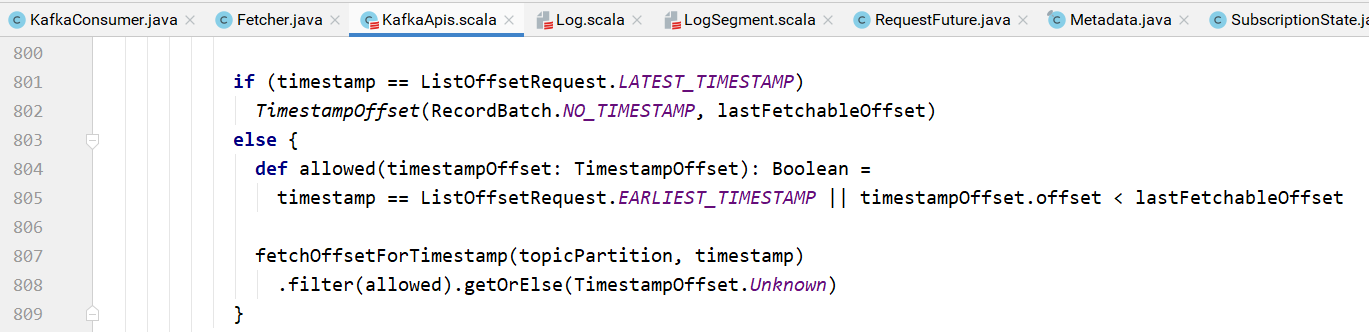
查找的逻辑:
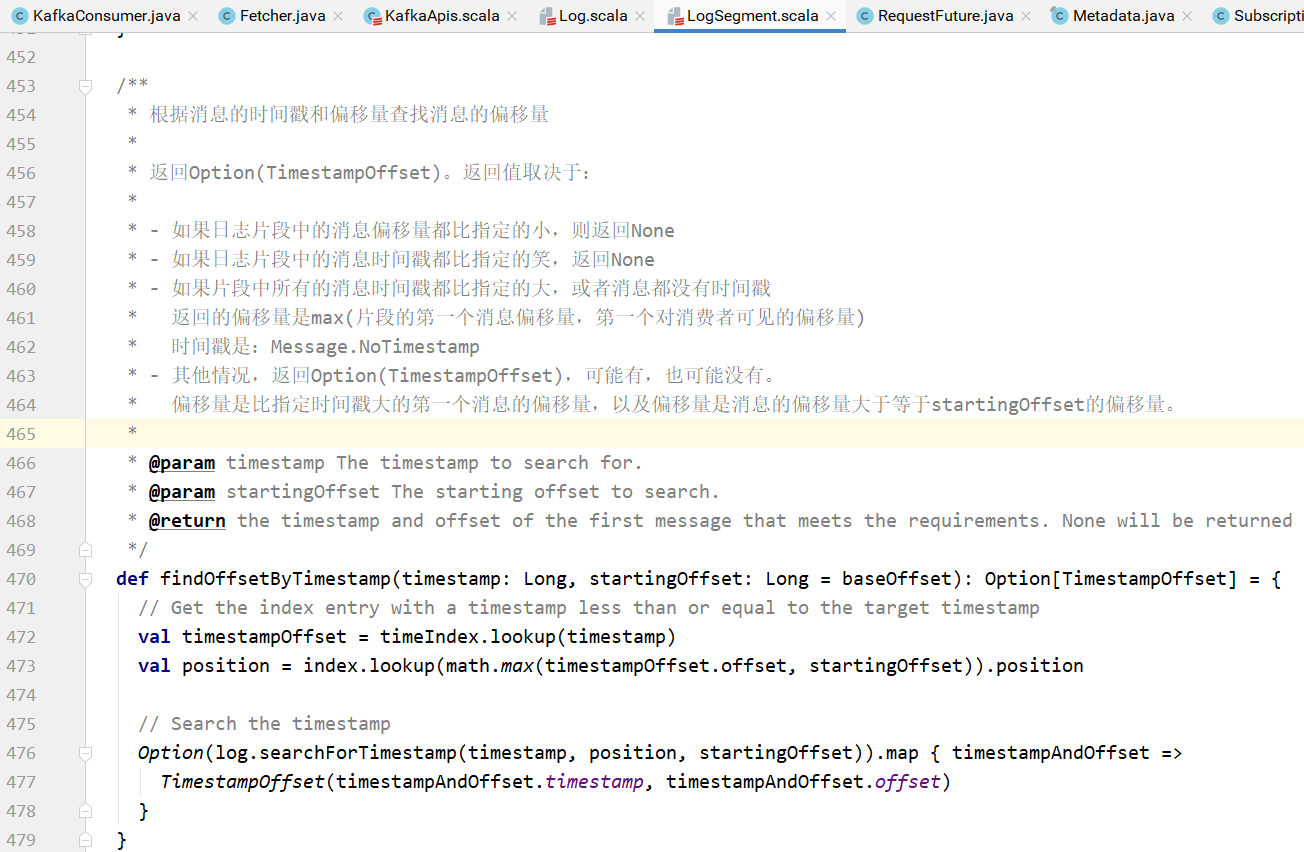
对于消费者,向指定的broker发送ListOffsetRequest请求,获取指定主题分区的偏移量和时间戳信息:

调用handleListOffsetResponse处理获取的偏移量信息:


complete方法用于完成请求。当complete方法调用之后,successed方法返回true。
同时偏移量信息可以通过value方法获取:
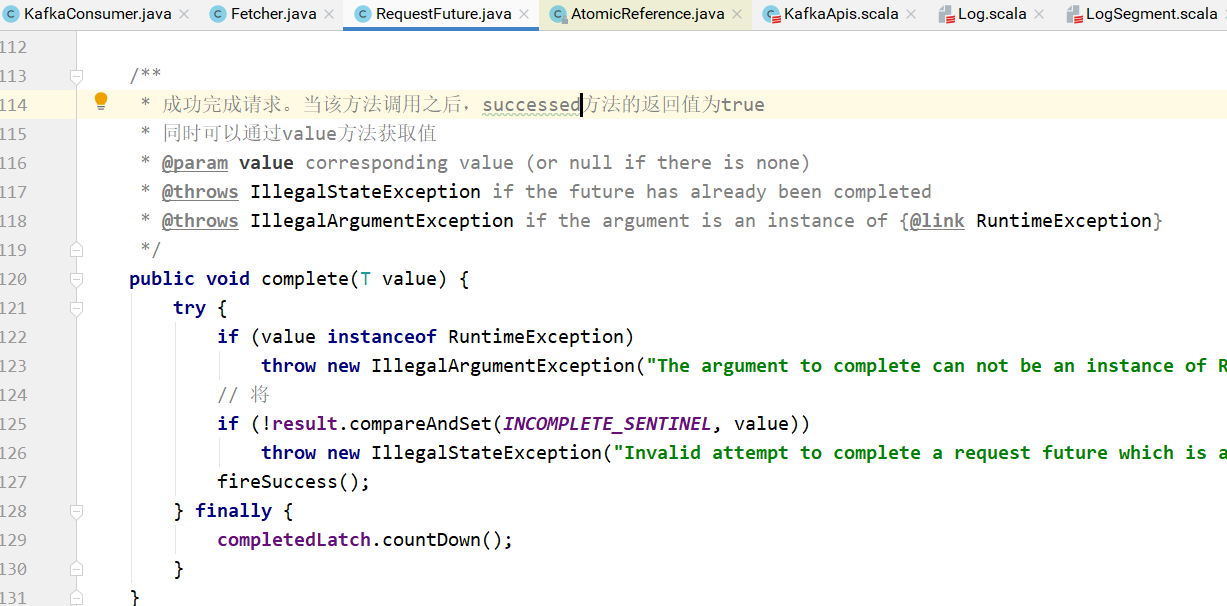
即:变量offsetsByTimes的值就是下图中future.value()的值。此时各个主题分区的偏移量已经设置好了:


pollOnce方法:

在更新主题分区的偏移量之后,就可以发送请求消费消息了:
对于组消费,还需要定期将偏移量提交到 __consumer_offsets 主题中:
poll方法的实现:

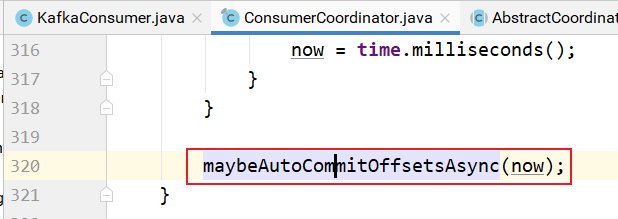
如果是自动提交消费者偏移量到broker的 __consumer_offsets 主题,则maybeAutoCommitOffsetsAsync的实现:
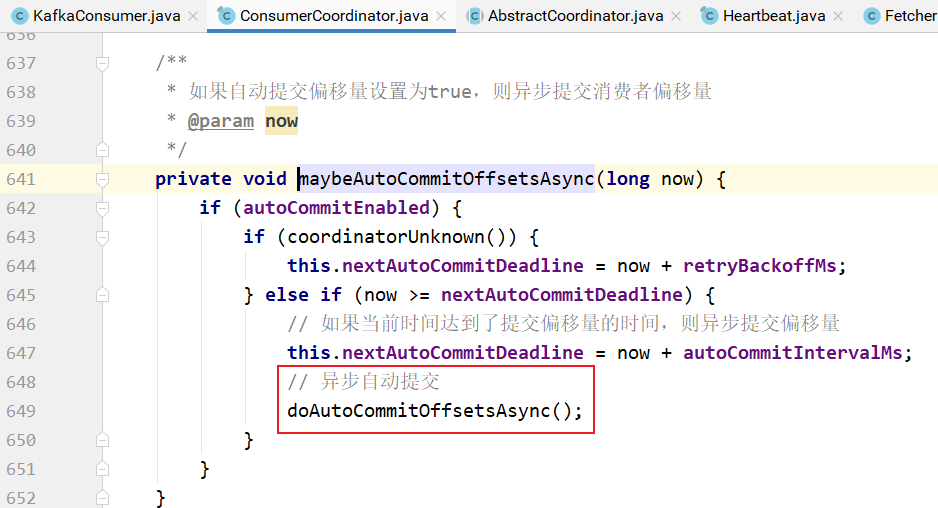
doAutoCommitOffsetsAsync的实现:
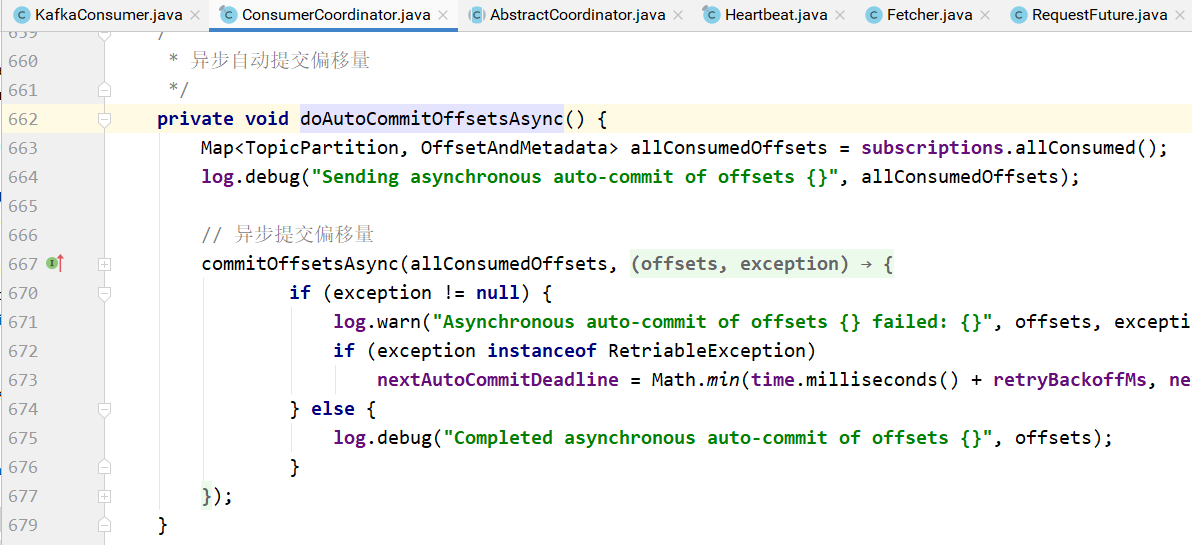
commitOffsetsAsync的实现:
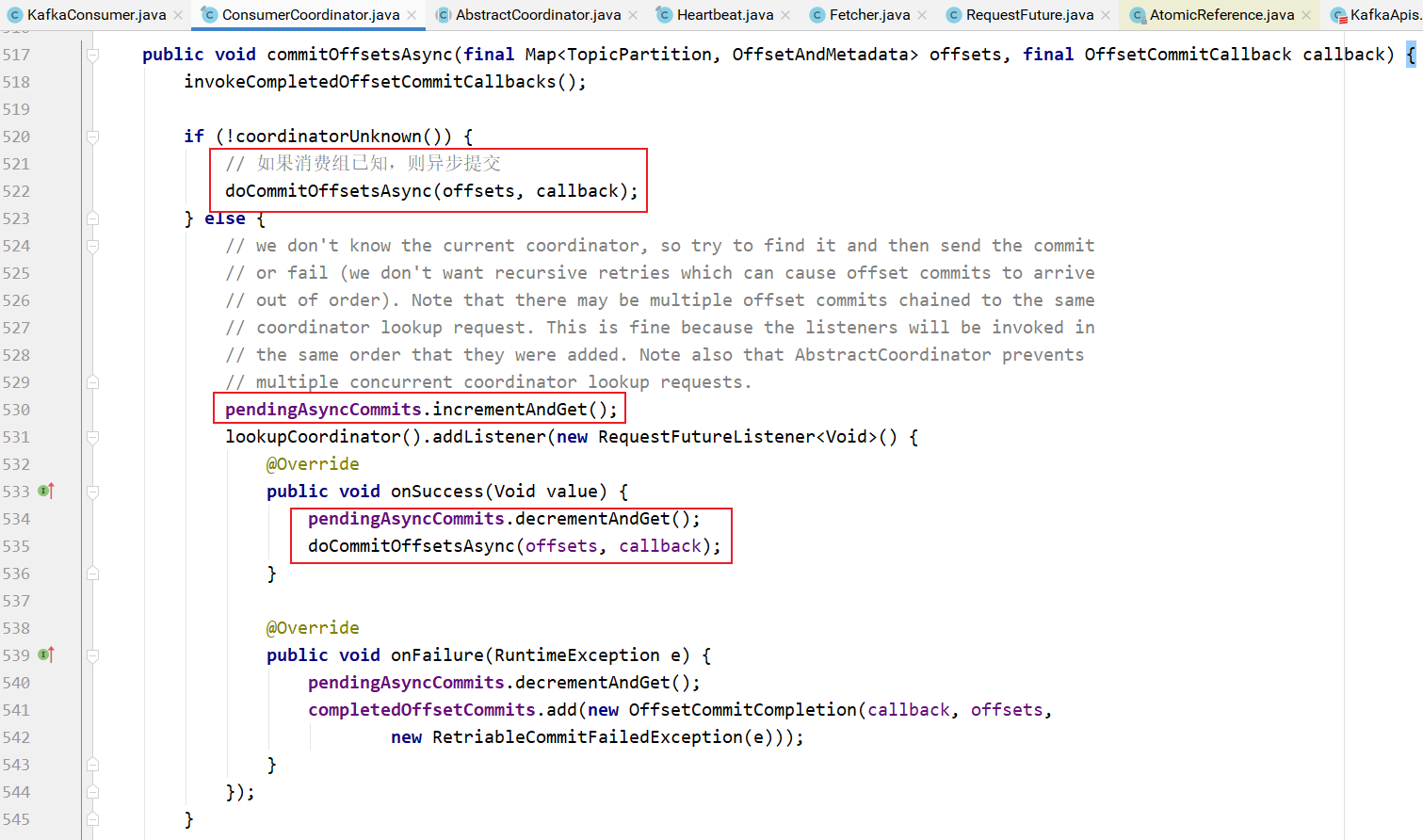
在异步提交消费者偏移量的时候,如果组协调器已知,直接发送
如果未知,则异步提交等待,查找组协调器,等找到之后,异步提交消费者偏移量:

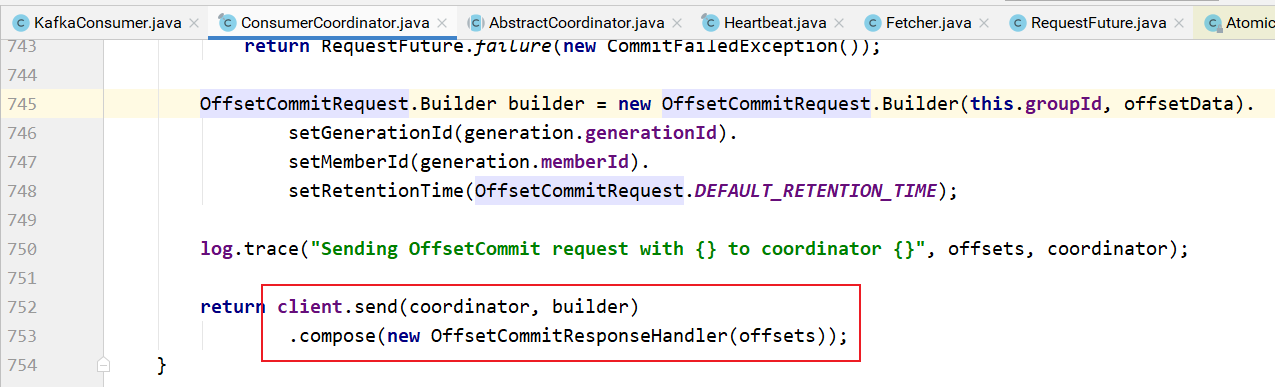
上图中sendOffsetCommitRequest的实现:
- 首先查找消费组协调器
- 然后创建偏移量提交请求对象
- 发送请求

在KafkaServer处理的时候:
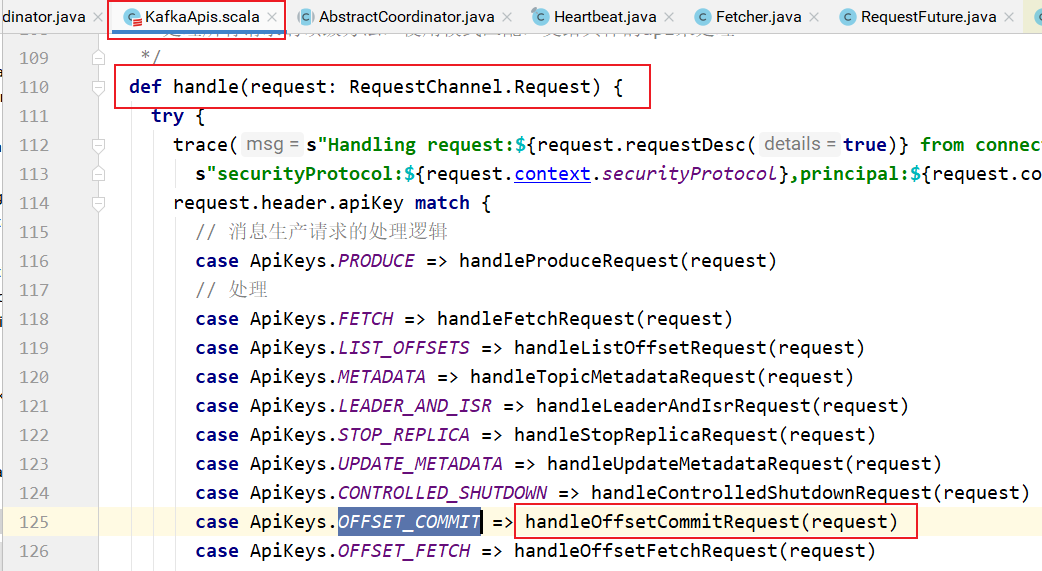
handleOffsetCommitRequest的实现:
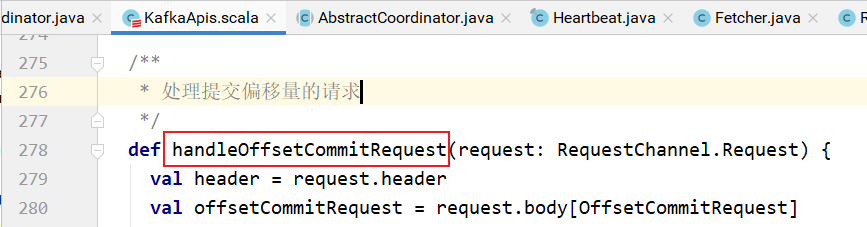

消费组协调器的处理:


doCommitOffsets的实现:


storeOffsets的实现:
其中:



appendForGroup的实现如下,将当前消费组的偏移量消息追加到 __consumer_offsets 的指定分区中:

