 对象创建
对象创建
前面我们介绍的是从class字节码文件加载到jvm内存的过程。
接下来,我们看jvm里的代码跑起来以后,在运行过程中,对象的创建和销毁在内存中经历了什么样的事情。
# 5.1 对象创建
# 5.1.1 概述
从你new一个对象开始,发生了什么?
遇到new指令,jvm首先要做的事是检查有没有这个类,没有的话,加载它!
# 5.1.2 内存分配
类加载检查通过后,就要给新对象分配内存。
因为一个类型确定后,它内部定义了哪些结构哪些值,所需要的内存空间也就确定了。先给他划出来。
(具体对象的内存布局,在下一小节)
但是这个内存分配,具体怎么划出来,有不同的方式:
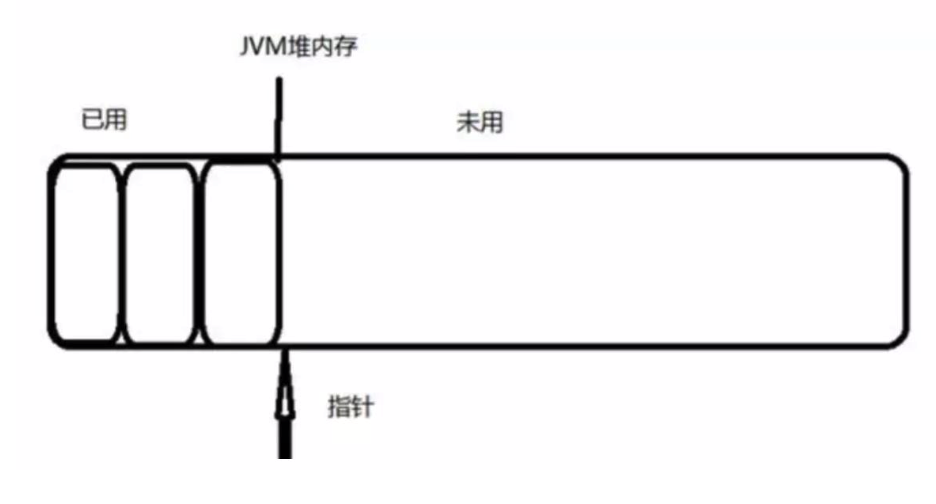
1)指针碰撞(Bump The Pointer)
这种分配前提是内存中有整片连续的空间,用的在一边,空闲的在另一边,一个指针指向分界线。
需要多少指针往空闲那边移动多少,直接划分出来一段,给当前对象,完工。
2)空闲列表(Free List)
那如果jvm堆不那么规整呢?用的和没用的交叉在一起,也就是我们所说的内存碎片。
这种情况就需要我们单独有一张表来记录,哪些内存块是空的。
分配的时候查表,找到大小够用的一块,分配给对象,同时更新列表。
具体哪种方式,和我们的垃圾回收器有关系。有的垃圾回收器会对内存做整理压缩,那就指针碰撞简单高效。如果没有压缩功能,那只能是采用空闲列表
这部分详细的垃圾回收在下面的第6小节(内容很多!)
3)并发性
无论指针移动还是空闲列表的同一个指针空间,在并发分配的情况下会不会有问题?
很聪明!确实有并发问题。那jvm是如何解决的呢?
方式一:cas原子操作 + 失败重试
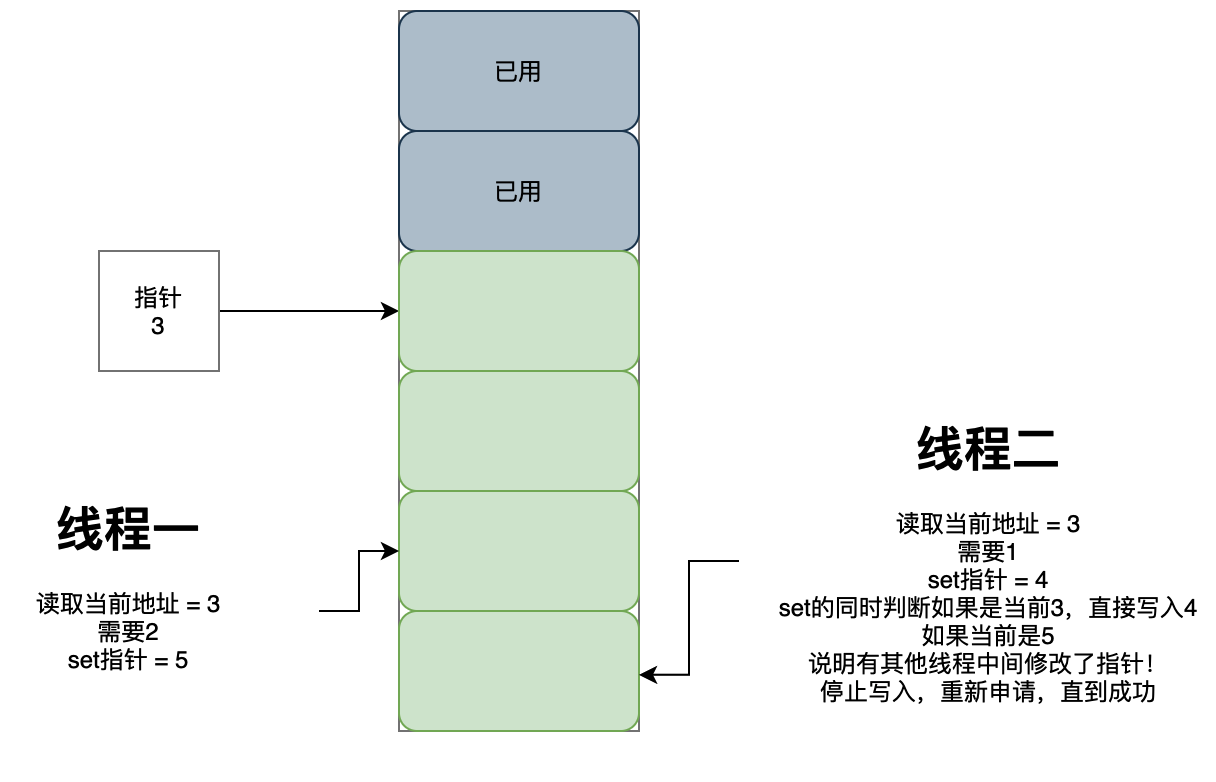
方式二:本地线程分配缓冲(TLAB)
全称是 Thread Local Allocation Buffer,需要 -XX:+/-UseTLAB
我们知道,对于栈、计数器,每个线程独享,堆是共享的。
但实际上,我们可以让线程在创建时,先独享划走一部分堆。
那么线程创建对象需要内存时,可以在自己划走的堆上先操作。相当于每个线程批发了一批内存先用着。
当前线程空间不够时,再去公共堆上申请,这样就减少了并发冲突的机会。当然也多少有点浪费
# 5.2 内存布局
上面我们给这个对象分配好了内存空间,那么问题来了。对象拿走的这块内存,它都写了些啥进去呢?
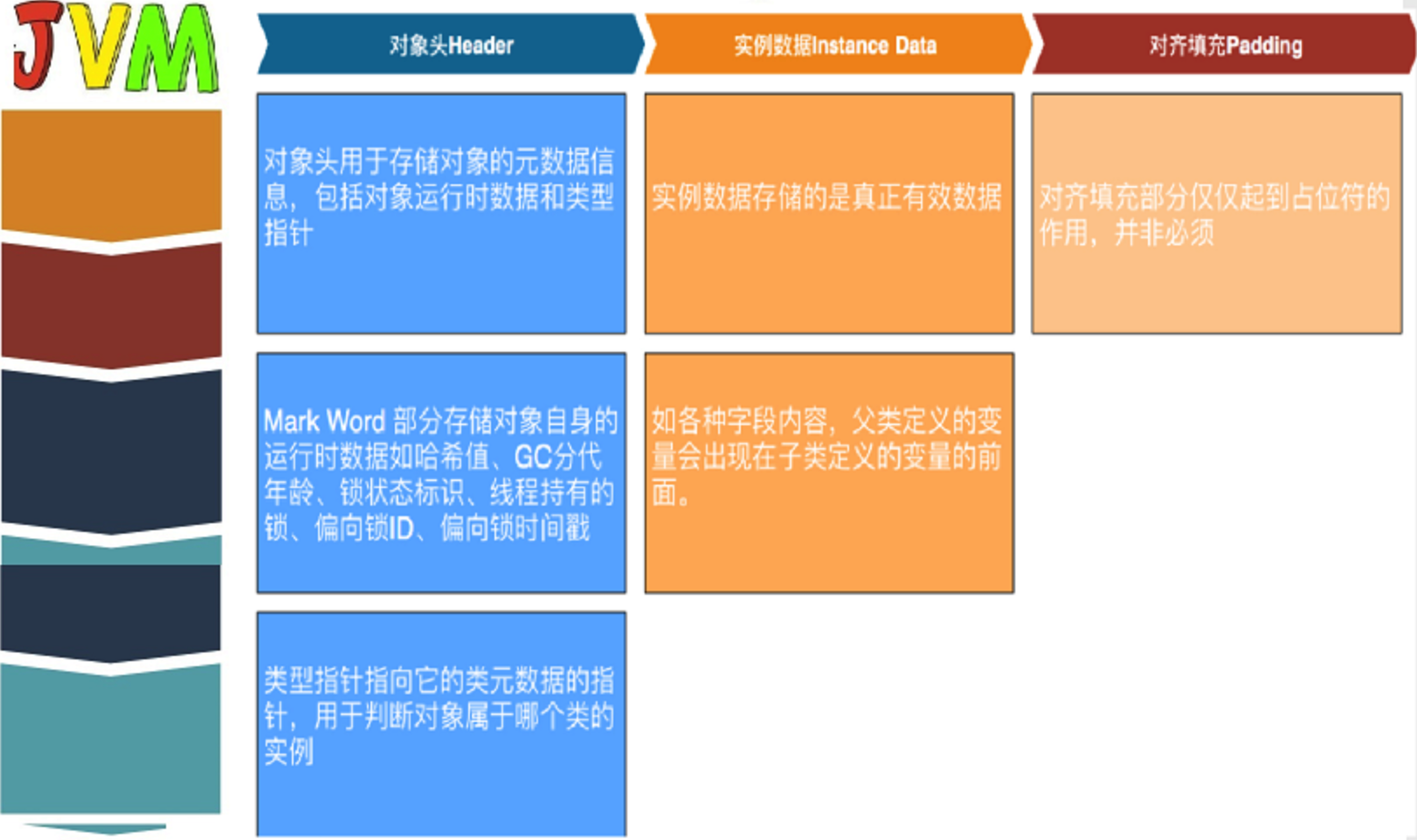
对象在堆上的布局,可以分为三个部分:对象头、实例数据、对齐填充。
# 5.2.1 对象头
对象头一般分为两部分,Mark Word 和 类型指针(Hotspot)
1)Mark Word,官方叫法,其实就是存储对象自己运行时的数据
如哈希码、GC分代年龄、锁状态标记、线程持有的锁、偏向的线程id……(不用记)
2)类型指针
指向当前对象的类型。也就是方法区里,类信息的地址。
当然这里不是绝对的,hotspot这么设计。在5.3对象访问一节,还会看到其他方式。
# 5.2.2 实例数据
对象里各个字段的值。这个好理解。
long,double,int等长度都是固定的
string、对象类型等是个地址,指向其他外部堆空间
# 5.2.3 对齐填充
不是必须的。就是个占位符而已。
Hotspot规定的,内存管理系统要求对象的大小必须是8字节的整数倍。
这个在对象头上,已经被精心设计过,满足要求。
但是!实例数据部分不一定。如果没有对齐的话,通过这里的对齐填充补满它。没有别的意义。
# 5.3 对象的访问
对象创建了,就要用,它在堆里。
我们的程序运行时,大家知道,每一个方法相关的变量信息都在栈里。那么怎么找到这个对象呢?
一般来讲,两种方案:
# 5.3.1 句柄访问
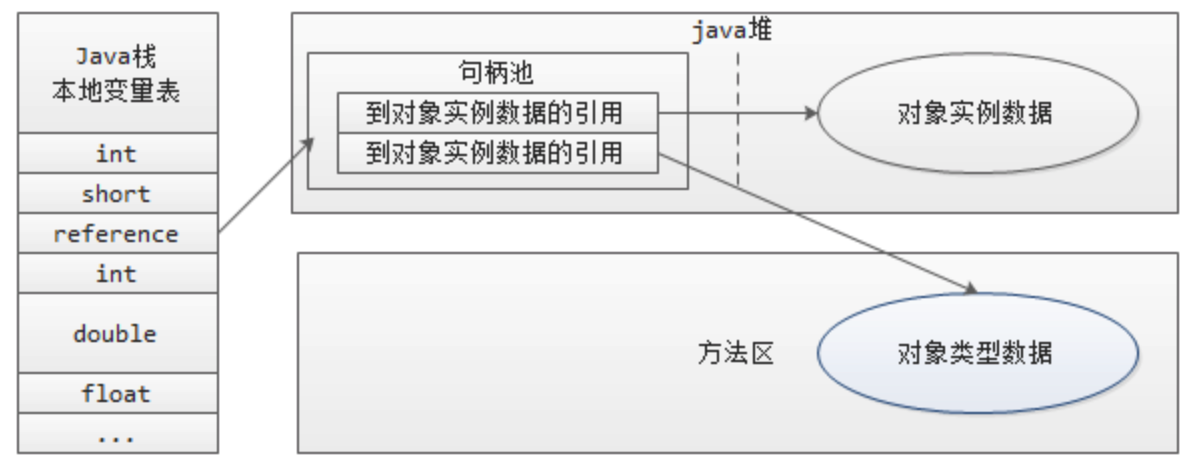
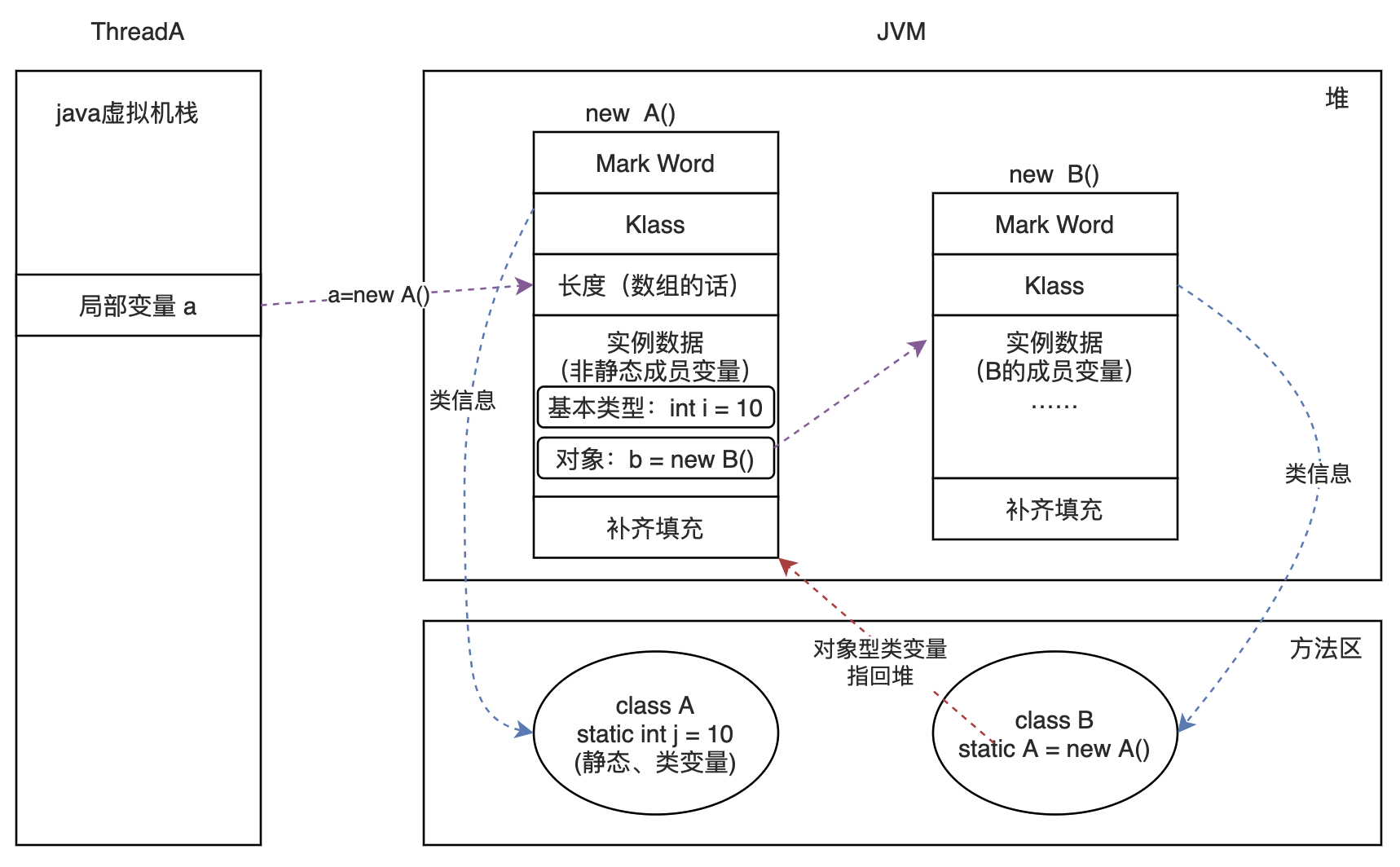
句柄方式:
栈指针指向堆里的一个句柄的地址,这个句柄再定义俩指针分别指向类型和实例
很显然,垃圾回收移动对象的话只需要改句柄即可,不会波及到栈,但是多了一次寻址操作
# 5.3.2 直接地址
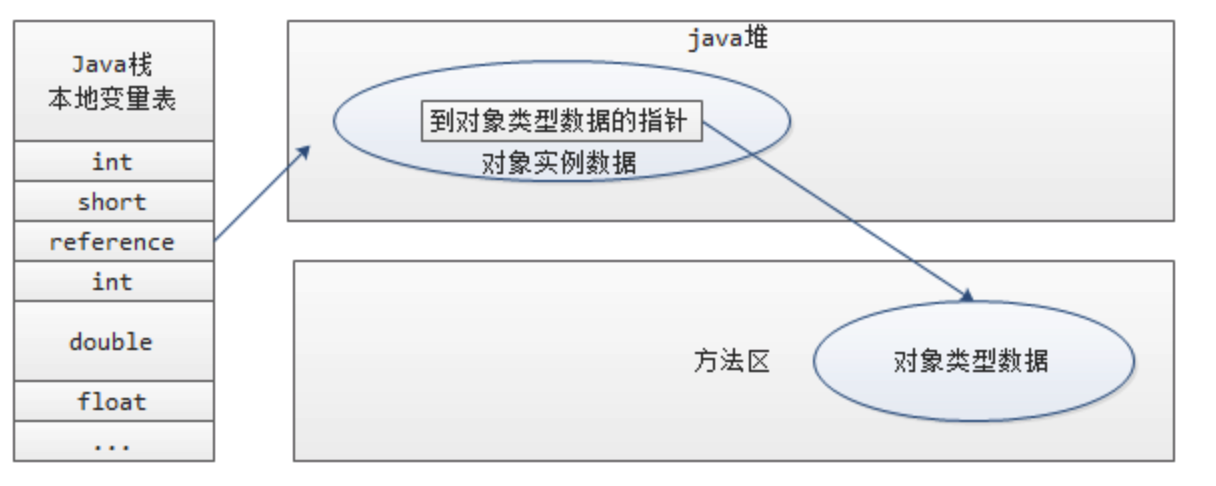
直接地址:
栈指针指向的就是实例本身的地址,在实例里封装一个指针指向它自己的类型
很显然,垃圾回收移动对象要改栈里的地址值,但是它减少了一次寻址操作。
备注:hostspot使用的是直接地址方式
